
Cloudflare指控Perplexity使用隐形爬虫逃避屏蔽
2025-08-05 08:17 loading...
互联网安全基础设施提供商Cloudflare近日披露,人工智能公司Perplexity在其客户明确设置屏蔽规则的情况下,仍持续抓取网页内容,涉嫌使用“隐形爬虫”规避限制。
Perplexity被指违规抓取,技术手段引争议
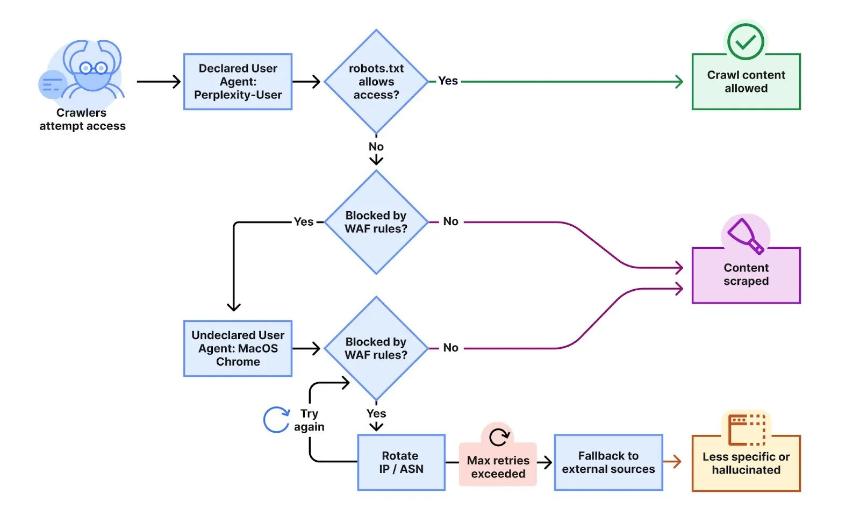
据Cloudflare工程师团队调查,尽管多个新注册域名已通过robots.txt文件和防火墙规则禁止访问,但Perplexity仍能返回受限制页面的具体信息。测试显示,该公司不仅使用声明的用户代理,还伪装成Google Chrome浏览器,在macOS环境下模拟真实用户行为。
更令人关注的是,这些未声明的爬虫采用了多重规避策略:使用不在官方IP范围内的地址、轮换不同ASN来源的请求,从而绕过屏蔽机制。数据显示,此类隐形爬虫每日生成300万至600万个请求,而公开声明的爬虫则达2000万至2500万次,涉及数万个域名。
Cloudflare强化防护,推动内容主权回归
面对日益严峻的AI爬虫挑战,Cloudflare宣布将所有客户纳入其“内容独立日”政策,默认阻止新域名上的AI爬虫访问。该举措旨在保护内容创作者免受非授权数据提取的影响。
截至目前,已有超过一百万个网站选择屏蔽AI爬虫,包括美联社、时代杂志、《大西洋月刊》、BuzzFeed、Reddit、Quora以及环球音乐集团等知名机构。这一趋势反映出全球数字内容生态对数据使用权的关注正在上升。
行业对比与未来应对策略
Cloudflare强调,OpenAI在被屏蔽时会遵守robots.txt指令并停止抓取,而Perplexity的行为则被认定为不合规。公司表示,透明性、目的明确性和遵循网站偏好是合法爬虫的基本标准。
为应对此类问题,Cloudflare已部署签名匹配功能,可自动识别并阻断可疑爬虫。同时,其正在研发“AI迷宫”工具,可将不合规机器人困于虚假内容环境中;此外,还计划推出按次付费市场,允许出版商向AI公司收取内容访问费用,构建可持续的内容价值体系。

市场反应与长期影响
此事件进一步凸显了当前人工智能发展与网络内容治理之间的张力。随着各大科技公司加速布局生成式AI,如何平衡数据获取效率与版权保护成为关键议题。若缺乏有效监管框架,可能导致优质内容生产者收益受损,进而影响整个数字生态的可持续性。
专家指出,此次冲突不仅是技术层面的问题,更是商业模式与伦理责任的考验。未来,建立标准化的AI访问协议、推动内容授权机制、加强平台自律将成为主流方向。
分享至






 相关阅读
相关阅读
-
买币前必看!白皮书如何帮你避开骗局WEB3.0 2025-07-20 16:25

-
Chainlink价格盘整背后:鲸鱼出货与长期布局并存区块链资讯 2025-12-22 00:26

-
Figure IPO募资7.875亿美元 登陆纳斯达克成RWA第一股区块链资讯 2025-09-12 02:19

-
2025Meme币热潮:SHIB/BONK/LILPEPE价格波动与市场趋势解析区块链资讯 2025-07-25 01:18

-
MoneyGram在哥伦比亚推USDC汇款应用,链上支付迎新突破区块链资讯 2025-09-18 03:18

-
TON Station每日特惠组合2025年11月24日:领取免费奖励攻略比特币资讯 2025-12-22 22:17

-
Shibarium桥遭闪电贷攻击,团队悬赏追回240万美元被盗资金名家专栏 2025-09-14 06:34

-
Kaito Earn代币发行后热度骤降:SKATE/HUMA/QUAI/SOON全复盘区块链资讯 2025-07-09 19:01

-
PENGU会重演7月暴涨吗?链上数据揭示关键信号名家专栏 2025-08-29 00:33

-
zkLend 宣布停止运营 将20万美元用于用户恢复基金区块链资讯 2025-06-26 04:15
